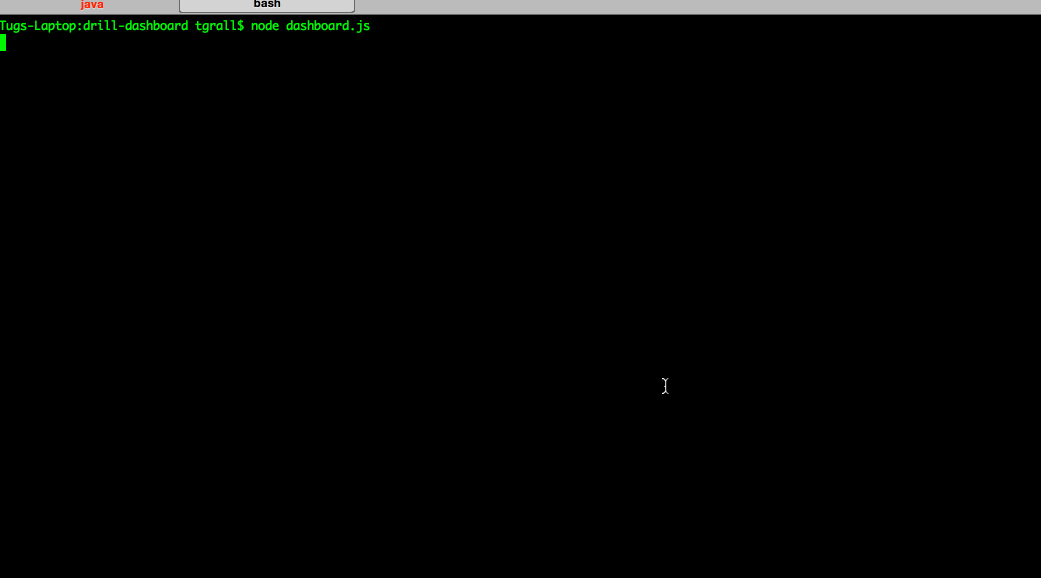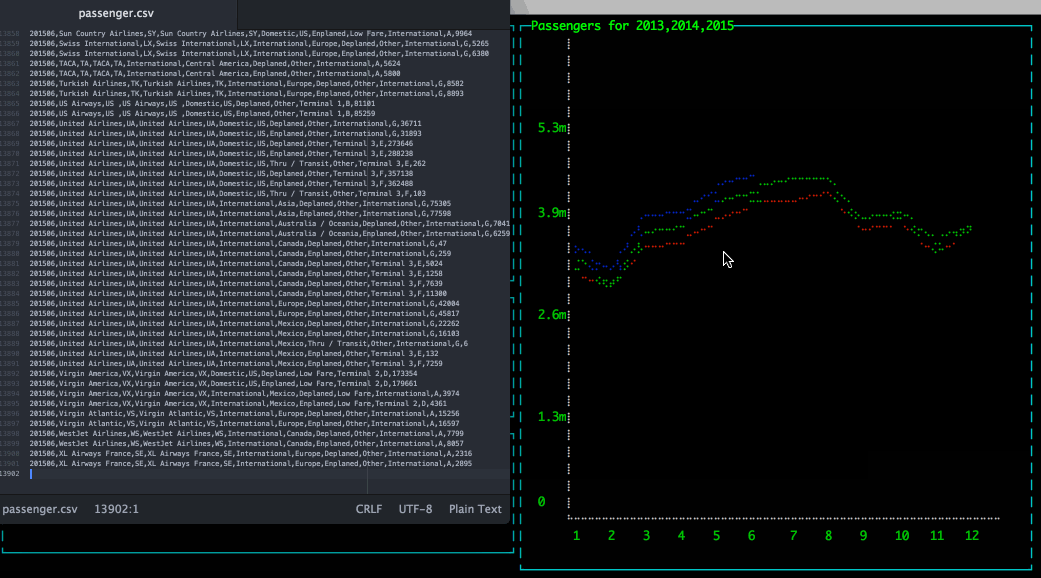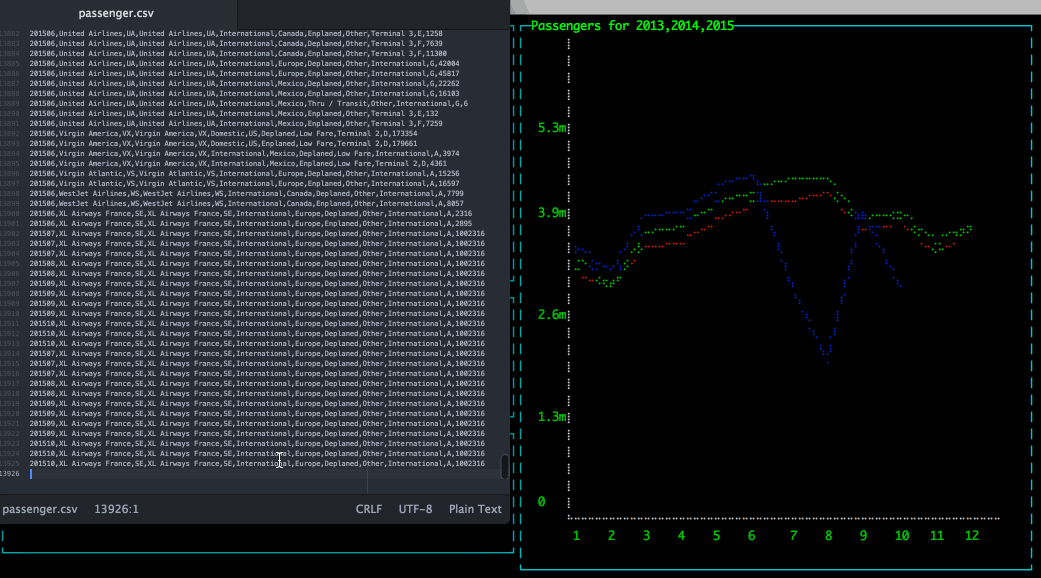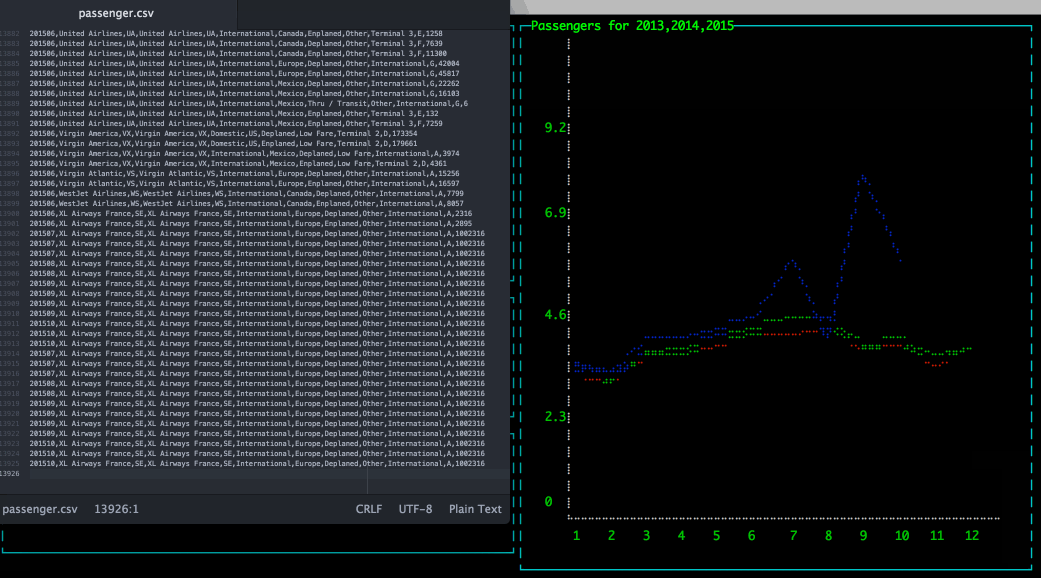
A very common use case when working with Hadoop is to store and query simple files (CSV, TSV, ...); then to get better performance and efficient storage convert these files into more efficient format, for example Apache Parquet.
Let's take a concrete example, you can find many interesting Open Data sources that distribute data as CSV files- or equivalent format-. So you can store them into your distributed file system and use them in your applications/jobs/analytics queries. This is not the most efficient way especially when we know that these data won't move that often. So instead of simply storing the CSV let's copy this information into Parquet.
How to convert CSV files into Parquet files?
You can use code to achieve this, as you can see in the ConvertUtils sample/test class. You can use a simpler way with Apache Drill. Drill allows you save the result of a query as Parquet files.
The following steps will show you how to do convert a simple CSV into a Parquet file using Drill.
Apache Drill allows users to explore any type of data using ANSI SQL. This is great, but Drill goes even further than that and allows you to create custom functions to extend the query engine. These custom functions have all the performance of any of the Drill primitive operations, but allowing that performance makes writing these functions a little trickier than you might expect.
In this article, I’ll explain step by step how to create and deploy a new function using a very basic example. Note that you can find lot of information about Drill Custom Functions in the documentation.
Let’s create a new function that allows you to mask some characters in a string, and let’s make it very simple. The new function will allow user to hide x number of characters from the start and replace then by any characters of their choice. This will look like:
1
MASK( 'PASSWORD' , '#' , 4 ) => ####WORD
You can find the full project in the following Github Repository.
As mentioned before, we could imagine many advanced features to this, but my goal is to focus on the steps to write a custom function, not
so much on what the function does.
Last week at the Paris MUG, I had a quick chat about security and MongoDB, and I have decided to create this post that explains how to configure out of the box security available in MongoDB.
You can find all information about MongoDB Security in following documentation chapter:
In this post, I won't go into the detail about how to deploy your database in a secured environment (DMZ/Network/IP/Location/...)
I will focus on Authentication and Authorization, and provide you the steps to secure the access to your database and data.
I have to mention that by default, when you install and start MongoDB, security is not enabled. Just to make it easier to work with.
The first part of the security is the Authentication, you have multiple choices documented here. Let's focus on "MONGODB-CR" mechanism.
The second part is Authorization to select what a user can do or not once he is connected to the database. The documentation about authorization is available here.
Let's now document how-to:
Create an Administrator User
Create Application Users
For each type of users I will show how to grant specific permissions.
We use the new X3 Platform based on MongoDB, Node.js and HTML to add cool features to the ERP
This shows that “any” enterprise can (should) do it to:
look differently at software development
build strong team spirit
have fun!
Introduction
I have like many of you participated to multiple Hackathons where developers, designer and entrepreneurs are working together to build applications in few hours/days. As you probably know more and more companies are running such events internally, it is the case for example at Facebook, Google, but also ING (bank), AXA (Insurance), and many more.
Last week, I have participated to the first Sage Hackathon!
In case you do not know Sage is a 30+ years old ERP vendor. I have to say that I could not imagine that coming from such company… Let me tell me more about it.
Last night the Nantes MUG (MongoDB Users Group) had its second event. More than 45 people signed up and joined us at the Epitech school (thanks for this!). We were lucky to have 2 talks from local community members:
First of all, if you do not know MyScript I invite you to play with the online demonstration. I am pretty sure that you are already using this technology without noticing it, since it is embedded in many devices/applications including: your car look at the Audi Touchpad!
That said Mathieu was not here to talk about the cool features and applications of MyScript but to explain how MongoDB is used to run their cloud product.
Mathieu explained how you can use MyScript SDK online. You just need to call a REST API to add Handwriting Recognition to your application. Let's make the long story short, and see how MongoDB was chosen and how it is used today:
The prototype was done with a single RDBMS instance
With the success of the project MyScript Cloud the team had to move to a more flexible solution:
Flexible schema to support heterogeneous structures,
Highly available solution with automatic failover,
Multi datacenter supports with localized read,
This is when Mathieu looked at different solution and selected MongoDB and deployed it on AWS.
Mathieu highlighted the following points:
Deploy and Manage a Replica Set is really easy, and it is done on multiple AWS data centers,
Use the proper read preference (nearest in this case) to deliver the data as fast as possible,
Develop with JSON Documents provides lot of flexibility to the developers, that can add new features faster.
Aggregation Framework
Sebastien "Seb" is software engineering at SERLI and working with MongoDB for more than 2 years now. Seb introduced the reasons why aggregations are needed in applications and the various ways of doing it with MongoDB: simple queries, map reduce, and aggregation pipeline; with a focus on a Aggregation Pipeline.
Using cool demonstrations, Seb explained in a step by step approach the key features and capabilities of MongoDB Aggregation Pipeline:
$match, $group, ...
$unwind arrays
$sort and $limit
$geonear
To close his presentation, Seb talked about aggregation best practices, and behavior in a sharded cluster.
And...
As usual the event ended with some drinks and a late dinner!
This event was really great and I am very happy to see what people are doing with MongoDB, including storing ink like MyScript, thanks again to the speakers!
This brings me to the last point : MUGs are driven by the community. You are using MongoDB and want to talk about what you, do not hesitate to reach out the organizers they will be more than happy to have you.
In this article we will see how to create a pub/sub application (messaging, chat, notification), and this fully based on MongoDB (without any message broker like RabbitMQ, JMS, ... ).
So, what needs to be done to achieve such thing:
an application "publish" a message. In our case, we simply save a document into MongoDB
another application, or thread, subscribe to these events and will received message automatically. In our case this means that the application should automatically receive newly created document out of MongoDB
As you can see in the documentation, Capped Collections are fixed sized collections, that work in a way similar to circular buffers: once a collection fills its allocated space, it makes room for new documents by overwriting the oldest documents.
MongoDB Capped Collections can be queried using Tailable Cursors, that are similar to the unix tail -f command. Your application continue to retrieve documents as they are inserted into the collection. I also like to call this a "continuous query".
Now that we have seen the basics, let's implement it.
Building a very basic application
Create the collection
The first thing to do is to create a new capped collection :
For simplicity, I am using the MongoDB Shell to create the messages collection in the chat database.
You can see on line #7 how to create a capped collection, with 2 options:
capped : true : this one is obvious
size : 10000 : this is a mandatory option when you create a capped collection. This is the maximum size in bytes. (will be raised to a multiple of 256)
Finally, on line #9, I insert a dummy document, this is also mandatory to be able to get the tailable cursor to work.
Write an application
Now that we have the collection, let's write some code. First in node.js:
From lines #1 to 5 I just connect to my local MongoDB instance.
Then on line #7, I get the messages collection.
And on line #10, I execute a find, using a tailable cursor, using specific options:
{} : no filter, so all documents will be returned
tailable : true : this one is clear, to say that we want to create a tailable cursor
awaitdata : true : to say that we wait for data before returning no data to the client
numberOfRetries : -1 : The number of times to retry on time out, -1 is infinite, so the application will keep trying
Line #11 just force the sort to the natural order,.
Then on line #12, the cursor returns the data, and the document is printed in the console each time it is inserted.
Test the Application
Start the application
node app.js
Insert documents in the messages collection, from the shell or any other tool.
You can find below a screencast showing this very basic application working:
The source code of this sample application in this Github repository, take the step-01 branch; clone this branch using: